數(shù)據(jù)湖存儲格式Hudi 核心原理與實踐應(yīng)用
隨著大數(shù)據(jù)時代的深入發(fā)展,企業(yè)對數(shù)據(jù)處理的實時性、一致性和管理效率提出了更高要求。傳統(tǒng)的數(shù)倉架構(gòu)與原始數(shù)據(jù)湖方案在處理更新刪除、增量消費、實時分析等場景時面臨挑戰(zhàn)。Apache Hudi(Hadoop Upserts Deletes and Incrementals)應(yīng)運而生,作為一種開源的數(shù)據(jù)湖存儲格式,它通過在HDFS或云存儲之上引入表、事務(wù)、高效索引等數(shù)據(jù)庫核心概念,為大數(shù)據(jù)處理與存儲服務(wù)帶來了革新。
一、Hudi的核心原理
Hudi的設(shè)計核心在于將存儲層(如HDFS)上的數(shù)據(jù)集組織成具有ACID事務(wù)支持的時間線(Timeline)管理的表,并提供了兩種基礎(chǔ)存儲類型:
- Copy-on-Write (COW) 表:
- 原理:在數(shù)據(jù)寫入時(無論是插入、更新還是刪除),Hudi會直接創(chuàng)建包含所有受影響記錄的新版本數(shù)據(jù)文件(Parquet格式),并同步更新元數(shù)據(jù)索引。查詢引擎始終讀取最新版本的文件。
- 特點:寫時合并,讀取性能高(直接讀最新文件),但寫入延遲較高且存在寫放大問題。適用于讀多寫少、對查詢延遲敏感的場景。
- Merge-on-Read (MOR) 表:
- 原理:將更新/刪除操作記錄到增量日志文件(Avro格式)中,并與基礎(chǔ)列式文件(Parquet格式)并存。在讀取時(或根據(jù)策略異步壓縮時),實時或異步地將增量日志與基礎(chǔ)文件合并,生成新的列式文件。
- 特點:讀時合并,寫入延遲低(只需寫增量日志),但讀取時需要合并,查詢延遲相對較高。適用于寫多讀少、對寫入延遲敏感且需要近實時分析的場景。
核心機制:
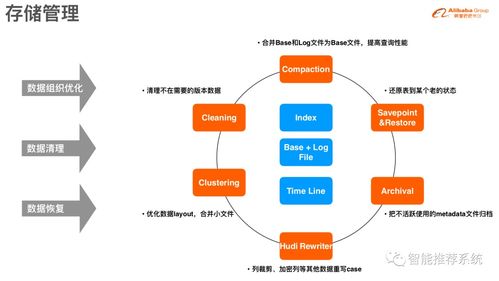
時間線 (Timeline):記錄所有對數(shù)據(jù)集的操作(提交、清理、壓縮等)及其狀態(tài),是保證ACID語義和實現(xiàn)時間旅行查詢的基礎(chǔ)。
索引 (Index):Hudi提供了多種索引(如布隆過濾器索引、HBase索引等),用于快速定位一條記錄存在于哪個文件,從而實現(xiàn)高效的Upsert和Delete,避免全表掃描。
* 表類型 & 查詢類型:結(jié)合COW/MOR表類型與快照查詢(讀取最新合并數(shù)據(jù))、增量查詢(讀取某個提交后新增的變更數(shù)據(jù))、讀優(yōu)化查詢(僅讀取MOR表的基礎(chǔ)列式文件)等多種查詢模式,為不同場景提供靈活的數(shù)據(jù)訪問視角。
二、Hudi在數(shù)據(jù)處理與存儲服務(wù)中的實踐
Hudi的價值在于它不僅僅是存儲格式,更是一套數(shù)據(jù)管理服務(wù)框架,能夠無縫集成Spark、Flink、Presto/Trino、Hive等主流計算查詢引擎。
1. 核心數(shù)據(jù)處理場景實踐:
高效的增量ETL管道:利用Hudi的增量查詢功能,可以輕松捕獲自上次處理以來的變更記錄,僅處理增量數(shù)據(jù)而非全量表,極大提升ETL效率,降低計算與IO成本。
近實時數(shù)據(jù)攝取與更新:通過Flink或Spark Streaming將Kafka等流式數(shù)據(jù)以Upsert方式寫入Hudi MOR表,可實現(xiàn)分鐘甚至秒級的延遲,并支持對歷史記錄的更新修正。
變更數(shù)據(jù)捕獲與同步:將數(shù)據(jù)庫的CDC數(shù)據(jù)直接寫入Hudi,構(gòu)建一個支持更新刪除的實時數(shù)據(jù)湖鏡像,便于下游消費和分析。
數(shù)據(jù)回溯與時間旅行:基于時間線,可以輕松查詢數(shù)據(jù)在歷史任意時間點的快照狀態(tài),滿足審計、故障排查、實驗回滾等需求。
2. 數(shù)據(jù)存儲與管理優(yōu)化實踐:
自動文件管理:Hudi自動處理小文件合并(壓縮),優(yōu)化文件大小和數(shù)量,提升查詢性能。同時提供清理(Clean)功能,刪除不再需要的舊文件版本,控制存儲成本。
統(tǒng)一批流存儲層:Hudi表可以同時作為批處理和流處理作業(yè)的源與目標,實現(xiàn)了批流存儲的統(tǒng)一,簡化了Lambda架構(gòu)的復雜性,助力向Kappa架構(gòu)演進。
* 數(shù)據(jù)治理與合規(guī):通過元數(shù)據(jù)管理、事務(wù)保障和數(shù)據(jù)生命周期策略(保留、清理),為數(shù)據(jù)湖提供更好的治理能力,滿足合規(guī)性要求。
三、最佳實踐與考量
在實踐中,成功部署Hudi需考慮以下幾點:
- 表類型選擇:根據(jù)讀寫模式(寫頻率、讀頻率、延遲要求)謹慎選擇COW或MOR。
- 索引選擇:根據(jù)數(shù)據(jù)規(guī)模和Upsert模式選擇合適索引,平衡寫入開銷與查詢性能。
- 資源配置與調(diào)優(yōu):合理設(shè)置壓縮(Compaction)、清理(Cleaning)策略的調(diào)度間隔和并行度,調(diào)整文件大小目標。
- 與現(xiàn)有生態(tài)集成:確保計算引擎(Spark/Flink版本)與Hudi版本的兼容性,并正確配置Catalog(如Hive Metastore)以支持多引擎查詢。
****
Apache Hudi通過將數(shù)據(jù)庫的事務(wù)、索引、高效更新等特性引入數(shù)據(jù)湖存儲層,有效解決了大數(shù)據(jù)場景下的增量處理、近實時更新和數(shù)據(jù)管理難題。它不僅是存儲格式的創(chuàng)新,更是構(gòu)建高效、可靠、易管理的數(shù)據(jù)湖平臺的關(guān)鍵服務(wù)組件。隨著云原生和實時分析需求的增長,深入理解Hudi原理并善用其最佳實踐,將成為構(gòu)建現(xiàn)代化數(shù)據(jù)處理與存儲服務(wù)體系的核心競爭力。
如若轉(zhuǎn)載,請注明出處:http://www.minfamumen.cn/product/84.html
更新時間:2026-05-30 02:05:25